2018年12月11日:习题讲解
第十、十二章
习题10.5
【题目】:
使用数据集acemoglu.dta。该数据集包含64个曾为欧洲殖民地的国家,主要变量为logpgp95(1995年人均GDP,PPP),avexpr(1985——1995年间的平均产权保护程度,0为最低,10为最高),lat_abst(首都纬度的绝对值/90),以及logem4(殖民者死亡率的对数)。另外,变量shortnam以三个字母表示每个国家的简称。
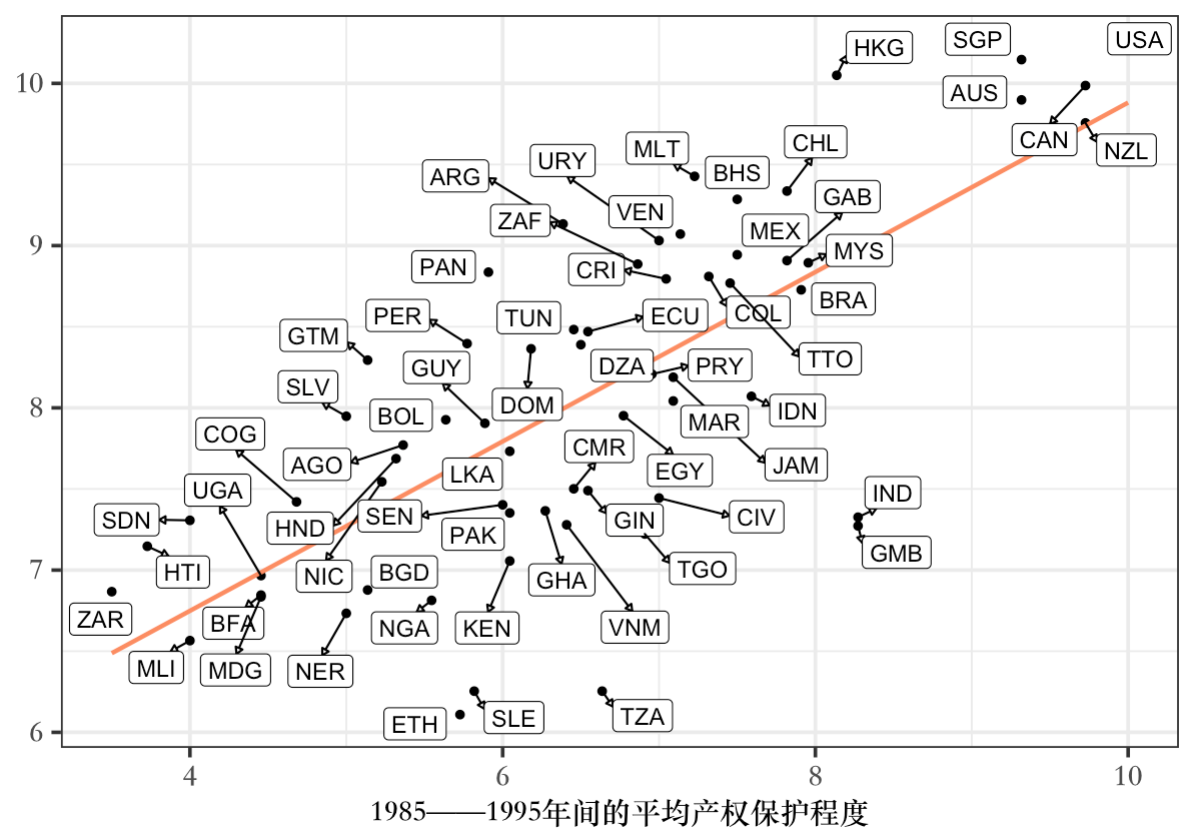
(1)为了直观地考察产权保护与经济发展的关系,将logpgp95和avexpr的散点图和线性拟合图画在一起,并为每个散点标注国家简称。
(2)为了使用稳健标准误,把logpgp95对avexpr及lat_abst进行回归,评论变量的符号、统计显著性及经济意义。
(3)由于avexpr可能为内生解释变量,使用logem4作为avexpr的工具变量,重新进行(2)回归。工具变量回归的结果与OLS有何不同?
(4)logem4是否为弱工具变量?
【解答】:
(1):散点图+线性拟合图+散点标签
cuse acemoglu, clear web
* 这里需要处理一下散点标签遮盖的问题
* ssc install egenmore
egen clock = mlabvpos(logpgp95 avexpr)
tw ///
sc logpgp95 avexpr, mlab(shortnam) mlabvpos(clock) || ///
lfit logpgp95 avexpr ||, ///
leg(order(1 "1995年PPP人均GDP" 2 "线性拟合值") pos(10) ring(0)) ///
xti("1985——1995年间的平均产权保护程度")
gr export "10_5散点图.png", replace

虽然还是不能完美的处理散点遮盖的问题,但是已经处理的相当不错了,如果你想追求完全没有任何散点遮盖,你可以逐个修改clock变量的某些值。不过R的ggplot2+ggrepel包能够完美的解决散点相互遮盖的问题。
# install.packages("RStata") # 读取数据的方法一:使用RStata包, # 该包的详细使用可以参考:https://www.czxa.top/posts/13184/ library(RStata) library(ggplot2) library(ggrepel) options("RStata.StataPath" = "/Applications/Stata/StataSE.app/Contents/MacOS/stata-se") options("RStata.StataVersion" = 15) s <- stata("cuse acemoglu, clear web", data.out = T) # 读取数据的方法二:使用readstata13包直接读取dta文件, # 之所以用这个包的原因是这个包读地最快。 library(readstata13) s <- read.dta13("acemoglu.dta") # 之所以为散点创建颜色映射,是因为我闲的无聊 ggplot(data = s, aes(x = avexpr, y = logpgp95, colour = shortnam)) + geom_point() + geom_smooth(method = "lm", se = F, colour = "#fc8d62") + geom_label_repel(arrow = arrow(length = unit(0.01, "npc"), type = "closed", ends = "first"), force = 10, aes(label = shortnam)) + labs(x = "1985——1995年间的平均产权保护程度") + theme(axis.title.y = element_blank()) + theme(legend.position = "none") + theme(axis.title.x = element_text(size = 14))

取消颜色映射:
ggplot(data = s, aes(x = avexpr, y = logpgp95)) +
geom_point() +
geom_smooth(method = "lm", se = F, colour = "#fc8d62") +
geom_label_repel(arrow = arrow(length = unit(0.01, "npc"),
type = "closed", ends = "first"),
force = 10,
aes(label = shortnam)) +
labs(x = "1985——1995年间的平均产权保护程度") +
theme(axis.title.y = element_blank()) +
theme(legend.position = "none") +
theme(axis.title.x = element_text(size = 14))
(2):稳健回归
. reg logpgp95 avexpr lat_abst, r
Linear regression Number of obs = 64
F(2, 61) = 64.91
Prob > F = 0.0000
R-squared = 0.5745
Root MSE = .69166
------------------------------------------------------------------------------
| Robust
logpgp95 | Coef. Std. Err. t P>|t| [95% Conf. Interval]
-------------+----------------------------------------------------------------
avexpr | .4678871 .0626811 7.46 0.000 .3425484 .5932257
lat_abst | 1.576884 .6506046 2.42 0.018 .2759197 2.877848
_cons | 4.728082 .3413732 13.85 0.000 4.045464 5.4107
------------------------------------------------------------------------------
- avexpr:符号为正,表示1985——1995年间的平均产权保护程度每提高1,1995年的PPP人均GDP平均提高47%。
- lat_abst:符号为正,表示纬度每上升1%,1995年的PPP人均GDP平均提高1.57%。
(3):IV
. ivregress 2sls logpgp95 (avexpr = logem4) lat_abst, r
Instrumental variables (2SLS) regression Number of obs = 64
Wald chi2(2) = 28.33
Prob > chi2 = 0.0000
R-squared = 0.1025
Root MSE = .9807
------------------------------------------------------------------------------
| Robust
logpgp95 | Coef. Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
avexpr | .995704 .2403256 4.14 0.000 .5246745 1.466734
lat_abst | -.6472071 1.227012 -0.53 0.598 -3.052107 1.757692
_cons | 1.691814 1.447779 1.17 0.243 -1.145781 4.529409
------------------------------------------------------------------------------
Instrumented: avexpr
Instruments: lat_abst logem4
IV的回归结果中avexpr的系数变大,lat_abst的系数由正变负,但是不再显著。
(4):弱工具变量检验
. estat first
First-stage regression summary statistics
--------------------------------------------------------------------------
| Adjusted Partial Robust
Variable | R-sq. R-sq. R-sq. F(1,61) Prob > F
-------------+------------------------------------------------------------
avexpr | 0.2960 0.2729 0.1767 9.52499 0.0030
--------------------------------------------------------------------------
由于F统计量小于10,因此无法拒绝存在弱工具变量的原假设,认为其是弱工具变量。
习题10.6
【题目】:
生育行为如何影响劳动力供给?具体来说,如果妇女多生一位小孩,其劳动力供给将下降多少?本题使用来自美国1980年人口普查的数据集fertility_small.dta进行估计。此数据集包含了美国21~35岁已婚且有两个或更多子女的妇女信息,主要变量为weeks(1979年的工作周数),morekids(是否有两个以上小孩),以及samesex(头两个小孩是否性别相同)。
(1)把weeks对虚拟变量morekids进行回归。有两个以上小孩的的妇女是否比有两个小孩的妇女工作更少?少多少?此效应是否在统计上显著?
(2)上面(1)的回归能否估计生育行为对劳动力供给的因果效应?为什么?
(3)把morekids对samesex进行回归。如果头两个小孩的性别相同,是否更可能生第三个小孩,此效应大么?是否在统计上显著?
(4)在weeks对morekids的回归中,能否将samesex作为有效工具变量?为什么?
(5)samesex是否为弱工具变量?
(6)以samesex为工具变量,把weeks对morekids进行回归。生育行为对劳动力供给的效应有多大?是否在统计上显著?
【解答】:
(1):OLS
cuse fertility_small.dta, clear
reg weeks morekids
结果:
Source | SS df MS Number of obs = 30,000
-------------+---------------------------------- F(1, 29998) = 538.16
Model | 254515.369 1 254515.369 Prob > F = 0.0000
Residual | 14187250.9 29,998 472.939893 R-squared = 0.0176
-------------+---------------------------------- Adj R-squared = 0.0176
Total | 14441766.3 29,999 481.408257 Root MSE = 21.747
------------------------------------------------------------------------------
weeks | Coef. Std. Err. t P>|t| [95% Conf. Interval]
-------------+----------------------------------------------------------------
morekids | -6.008217 .2589951 -23.20 0.000 -6.515858 -5.500575
_cons | 21.4782 .1591503 134.96 0.000 21.16626 21.79014
------------------------------------------------------------------------------
从结果可以看出,有两个以上小孩的妇女确实比只有两个孩子的妇女的工作时间更少,在5%的显著性水平上显著,平均每周少6个小时。
(2):因果判断
显然是不能的,这里面存在逆向因果的问题,也就是妇女可能会因为有闲暇时间而选择生孩子。
(3):回归
. reg morekids samesex
Source | SS df MS Number of obs = 30,000
-------------+---------------------------------- F(1, 29998) = 143.15
Model | 33.4852461 1 33.4852461 Prob > F = 0.0000
Residual | 7017.06195 29,998 .23391766 R-squared = 0.0047
-------------+---------------------------------- Adj R-squared = 0.0047
Total | 7050.5472 29,999 .235026074 Root MSE = .48365
------------------------------------------------------------------------------
morekids | Coef. Std. Err. t P>|t| [95% Conf. Interval]
-------------+----------------------------------------------------------------
samesex | .0668197 .0055848 11.96 0.000 .0558732 .0777662
_cons | .3439785 .0039616 86.83 0.000 .3362137 .3517433
------------------------------------------------------------------------------
结果显著为正,表明如果前两个孩子性别相同,更可能生第三个孩子。但是效应不大。
(4):IV
从逻辑上分析samesex变量影响morekids(相关性),且weeks不会影响samesex(外生性),所以samesex是一个很好的工具变量。
(5):弱工具变量的检验
. ivregress 2sls weeks (morekids = samesex), r
Instrumental variables (2SLS) regression Number of obs = 30,000
Wald chi2(1) = 2.58
Prob > chi2 = 0.1084
R-squared = 0.0176
Root MSE = 21.746
------------------------------------------------------------------------------
| Robust
weeks | Coef. Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
morekids | -6.033194 3.758162 -1.61 0.108 -13.39906 1.332668
_cons | 21.48763 1.425247 15.08 0.000 18.6942 24.28107
------------------------------------------------------------------------------
Instrumented: morekids
Instruments: samesex
. estat first
First-stage regression summary statistics
--------------------------------------------------------------------------
| Adjusted Partial Robust
Variable | R-sq. R-sq. R-sq. F(1,29998) Prob > F
-------------+------------------------------------------------------------
morekids | 0.0047 0.0047 0.0047 143.213 0.0000
--------------------------------------------------------------------------
对工具变量的有效性检验表明,F > 10,因此拒绝samesex是弱工具变量的原假设。
(6):IV
(5)中的回归结果表明生育行为对劳动力的供给确实会存在影响,具体来说,生育超过两个孩子的妇女平均比只生育两个孩子的妇女每周少工作6个小时。结果并不显著的。
(7):增加控制变量
回归略;结果发生了变化,因为这些被遗漏的控制变量会对生育行为产生影响。
习题12.3
【题目】:
数据集munnell.dta包含了美国48个州、1970——1986年的年度数据。为了估计公共资本对经济增长的贡献,使用此数据集进行以下回归:
其中,y为州产值(gross state product),$k_1$为公共资本,$k_2$为私人资本存量,labor为非农劳动力,unemp为州失业率(反映影响产出的经济周期因素)。面板变量为state,时间变量为year。
(1)进行混合回归,评论$lnk_1$的系数符号、显著性与经济意义。
(2)对随机效应模型进行FGLS估计。$lnk_1$的系数符号与显著性是否有变化?检验是否存在个体随机效应。
(3)对随机效应模型进行MLE估计。
(4)对固定效应模型进行组内估计。$lnk_1$的系数符号与显著性是否有变化?
(5)对固定效应进行LSDV估计, 检验是否存在个体固定效应。
(6)进行传统的豪斯曼检验。
(7)进行稳健的豪斯曼检验。
(8)在组内估计中,加入时间趋势项。时间趋势项是否显著?
(9)在组内估计中,加入时间虚拟变量,估计双向固定效应模型。时间效应是否显著?
(10)计算一阶差分估计量。$lnk_1$的系数符号与显著性是否有变化?
(11)计算组间估计量。此估计量是否可信?
【解答】:
(1):混合回归
cuse munnell, clear
xtset state year
reg lny lnk1 lnk2 lnlabor unemp, vce(cluster state)
结果:
. reg lny lnk1 lnk2 lnlabor unemp, vce(cluster state)
Linear regression Number of obs = 816
F(4, 47) = 2706.83
Prob > F = 0.0000
R-squared = 0.9926
Root MSE = .0881
(Std. Err. adjusted for 48 clusters in state)
------------------------------------------------------------------------------
| Robust
lny | Coef. Std. Err. t P>|t| [95% Conf. Interval]
-------------+----------------------------------------------------------------
lnk1 | .155007 .0609054 2.55 0.014 .0324812 .2775328
lnk2 | .3091902 .046834 6.60 0.000 .2149723 .403408
lnlabor | .5939349 .0695029 8.55 0.000 .4541131 .7337567
unemp | -.006733 .0031308 -2.15 0.037 -.0130314 -.0004346
_cons | 1.643302 .247374 6.64 0.000 1.14565 2.140955
------------------------------------------------------------------------------
$lnk_1$的系数为正,在5%的显著性水平上显著。经济意义是公共资本每增加1%,州产值平均增加0.155%。
(2):随机效应 + FGLS
. xtreg lny lnk1 lnk2 lnlabor unemp, r theta
Random-effects GLS regression Number of obs = 816
Group variable: state Number of groups = 48
R-sq: Obs per group:
within = 0.9412 min = 17
between = 0.9928 avg = 17.0
overall = 0.9917 max = 17
Wald chi2(4) = 4408.64
corr(u_i, X) = 0 (assumed) Prob > chi2 = 0.0000
theta = .8888353
(Std. Err. adjusted for 48 clusters in state)
------------------------------------------------------------------------------
| Robust
lny | Coef. Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
lnk1 | .0044388 .0553107 0.08 0.936 -.1039682 .1128458
lnk2 | .3105483 .044162 7.03 0.000 .2239923 .3971043
lnlabor | .7296705 .0708825 10.29 0.000 .5907434 .8685976
unemp | -.0061725 .0023631 -2.61 0.009 -.0108041 -.0015409
_cons | 2.135411 .2417872 8.83 0.000 1.661516 2.609305
-------------+----------------------------------------------------------------
sigma_u | .0826905
sigma_e | .03813705
rho | .82460109 (fraction of variance due to u_i)
------------------------------------------------------------------------------
此时不再显著。为了检验个体效应,下面进行LM检验:
. xttest0
Breusch and Pagan Lagrangian multiplier test for random effects
lny[state,t] = Xb + u[state] + e[state,t]
Estimated results:
| Var sd = sqrt(Var)
---------+-----------------------------
lny | 1.04271 1.021132
e | .0014544 .0381371
u | .0068377 .0826905
Test: Var(u) = 0
chibar2(01) = 4134.96
Prob > chibar2 = 0.0000
结果强烈拒绝“不存在个体随机效应的假设”,即认为存在个体效应。
(3):随机效应 + MLE
. xtreg lny lnk1 lnk2 lnlabor unemp, mle nolog
Random-effects ML regression Number of obs = 816
Group variable: state Number of groups = 48
Random effects u_i ~ Gaussian Obs per group:
min = 17
avg = 17.0
max = 17
LR chi2(4) = 2412.91
Log likelihood = 1401.9041 Prob > chi2 = 0.0000
------------------------------------------------------------------------------
lny | Coef. Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
lnk1 | .0031446 .0239185 0.13 0.895 -.0437348 .050024
lnk2 | .309811 .020081 15.43 0.000 .270453 .349169
lnlabor | .7313372 .0256936 28.46 0.000 .6809787 .7816957
unemp | -.0061382 .0009143 -6.71 0.000 -.0079302 -.0043462
_cons | 2.143865 .1376582 15.57 0.000 1.87406 2.413671
-------------+----------------------------------------------------------------
/sigma_u | .085162 .0090452 .0691573 .1048706
/sigma_e | .0380836 .0009735 .0362226 .0400402
rho | .8333481 .0304597 .7668537 .8861754
------------------------------------------------------------------------------
LR test of sigma_u=0: chibar2(01) = 1149.84 Prob >= chibar2 = 0.000
(4):固定效应 + 组内估计
. xtreg lny lnk1 lnk2 lnlabor unemp, fe r
Fixed-effects (within) regression Number of obs = 816
Group variable: state Number of groups = 48
R-sq: Obs per group:
within = 0.9413 min = 17
between = 0.9921 avg = 17.0
overall = 0.9910 max = 17
F(4,47) = 395.61
corr(u_i, Xb) = 0.0608 Prob > F = 0.0000
(Std. Err. adjusted for 48 clusters in state)
------------------------------------------------------------------------------
| Robust
lny | Coef. Std. Err. t P>|t| [95% Conf. Interval]
-------------+----------------------------------------------------------------
lnk1 | -.0261493 .0611148 -0.43 0.671 -.1490964 .0967978
lnk2 | .2920067 .0625495 4.67 0.000 .1661733 .4178401
lnlabor | .7681595 .0827326 9.28 0.000 .601723 .934596
unemp | -.0052977 .0025285 -2.10 0.042 -.0103844 -.0002111
_cons | 2.352898 .314594 7.48 0.000 1.720017 2.98578
-------------+----------------------------------------------------------------
sigma_u | .09057293
sigma_e | .03813705
rho | .8494045 (fraction of variance due to u_i)
------------------------------------------------------------------------------
$lnk_1$的符号变为负,同样不显著。
(5):固定效应 + LSDV
. xtreg lny lnk1 lnk2 lnlabor unemp i.state, vce(cluster state)
Random-effects GLS regression Number of obs = 816
Group variable: state Number of groups = 48
R-sq: Obs per group:
within = 0.9413 min = 17
between = 1.0000 avg = 17.0
overall = 0.9987 max = 17
Wald chi2(4) = .
corr(u_i, X) = 0 (assumed) Prob > chi2 = .
(Std. Err. adjusted for 48 clusters in state)
---------------------------------------------------------------------------------
| Robust
lny | Coef. Std. Err. z P>|z| [95% Conf. Interval]
----------------+----------------------------------------------------------------
lnk1 | -.0261493 .0629666 -0.42 0.678 -.1495615 .0972629
lnk2 | .2920067 .0644448 4.53 0.000 .1656972 .4183162
lnlabor | .7681595 .0852394 9.01 0.000 .6010934 .9352256
unemp | -.0052977 .0026051 -2.03 0.042 -.0104036 -.0001919
|
state |
ARIZONA | .1664708 .0131244 12.68 0.000 .1407475 .1921942
ARKANSAS | .0613989 .0201529 3.05 0.002 .0218998 .1008979
CALIFORNIA | .2988061 .0732358 4.08 0.000 .1552666 .4423455
COLORADO | .1942932 .0086412 22.48 0.000 .1773568 .2112296
CONNECTICUT | .2695868 .0341927 7.88 0.000 .2025704 .3366032
DELAWARE | .2118447 .0451819 4.69 0.000 .1232898 .3003996
FLORIDA | .1315363 .0385407 3.41 0.001 .0559979 .2070746
GEORGIA | .0565913 .0241312 2.35 0.019 .0092949 .1038876
IDAHO | .1367973 .0457483 2.99 0.003 .0471321 .2264624
ILLINOIS | .1857042 .0448826 4.14 0.000 .0977359 .2736726
INDIANA | .0577659 .0161645 3.57 0.000 .026084 .0894479
IOWA | .1255467 .0159194 7.89 0.000 .0943453 .1567482
KANSAS | .1371023 .0257417 5.33 0.000 .0866494 .1875551
KENTUCKY | .1976712 .0128558 15.38 0.000 .1724743 .2228682
LOUISIANA | .3130538 .0447378 7.00 0.000 .2253693 .4007384
MAINE | .0667996 .0397777 1.68 0.093 -.0111633 .1447626
MARYLAND | .1986622 .0368114 5.40 0.000 .1265132 .2708113
MASSACHUSETTS | .1606044 .0505757 3.18 0.001 .0614778 .2597309
MICHIGAN | .2153771 .0384914 5.60 0.000 .1399354 .2908188
MINNESOTA | .1139324 .0209493 5.44 0.000 .0728724 .1549923
MISSISSIPPI | .0484076 .0145654 3.32 0.001 .01986 .0769552
MISSOURI | .1120074 .0205456 5.45 0.000 .0717388 .152276
MONTANA | .1465373 .0661967 2.21 0.027 .0167942 .2762804
NEBRASKA | .1096629 .0355752 3.08 0.002 .0399369 .179389
NEVADA | .1402696 .0459828 3.05 0.002 .050145 .2303941
NEW_HAMPSHIRE | .1225309 .0446646 2.74 0.006 .0349898 .2100719
NEW_JERSEY | .2412521 .0422531 5.71 0.000 .1584374 .3240667
NEW_MEXICO | .2527582 .0460158 5.49 0.000 .1625689 .3429476
NEW_YORK | .2743703 .077557 3.54 0.000 .1223614 .4263792
NORTH_CAROLINA | .0360083 .030923 1.16 0.244 -.0245997 .0966164
NORTH_DAKOTA | .1422781 .0748141 1.90 0.057 -.0043548 .288911
OHIO | .1210272 .0431546 2.80 0.005 .0364457 .2056087
OKLAHOMA | .2143161 .0255197 8.40 0.000 .1642985 .2643337
OREGON | .1492874 .0121212 12.32 0.000 .1255303 .1730444
PENNSYLVANIA | .0877255 .0488119 1.80 0.072 -.0079441 .1833952
RHODE_ISLAND | .1867343 .0561357 3.33 0.001 .0767105 .2967582
SOUTH_CAROLINA | -.082223 .0207814 -3.96 0.000 -.1229539 -.0414922
SOUTH_DAKOTA | .0880636 .0596279 1.48 0.140 -.028805 .2049322
TENNESSE | .0274807 .0188807 1.46 0.146 -.0095248 .0644862
TEXAS | .1920419 .0443789 4.33 0.000 .1050609 .2790229
UTAH | .1270401 .0261314 4.86 0.000 .0758236 .1782566
VERMONT | .1345834 .0546054 2.46 0.014 .0275587 .2416081
VIRGINIA | .1788493 .0311795 5.74 0.000 .1177386 .2399599
WASHINGTON | .2451644 .0331981 7.38 0.000 .1800973 .3102315
WEST_VIRGINIA | .0915334 .0315848 2.90 0.004 .0296284 .1534383
WISCONSIN | .1273426 .0258475 4.93 0.000 .0766825 .1780027
WYOMING | .4469402 .1067769 4.19 0.000 .2376613 .6562192
|
_cons | 2.201616 .3258801 6.76 0.000 1.562903 2.840329
----------------+----------------------------------------------------------------
sigma_u | 0
sigma_e | .03813705
rho | 0 (fraction of variance due to u_i)
---------------------------------------------------------------------------------
从估计结果中可以看出,基本所有州的估计系数都是显著的,因此可以放心拒绝“所有个体虚拟变量的系数都为0”的原假设,即认为存在个体固定效应。
(6):传统的Hausman检验
qui xtreg lny lnk1 lnk2 lnlabor unemp, re
est store RE
qui xtreg lny lnk1 lnk2 lnlabor unemp, fe
est store FE
hausman FE RE, constant sigmamore
结果:
. hausman FE RE, constant sigmamore
---- Coefficients ----
| (b) (B) (b-B) sqrt(diag(V_b-V_B))
| FE RE Difference S.E.
-------------+----------------------------------------------------------------
lnk1 | -.0261493 .0044388 -.0305881 .0172815
lnk2 | .2920067 .3105483 -.0185416 .0155955
lnlabor | .7681595 .7296705 .038489 .0170552
unemp | -.0052977 -.0061725 .0008747 .0004016
_cons | 2.352898 2.135411 .2174875 .1138557
------------------------------------------------------------------------------
b = consistent under Ho and Ha; obtained from xtreg
B = inconsistent under Ha, efficient under Ho; obtained from xtreg
Test: Ho: difference in coefficients not systematic
chi2(5) = (b-B)‘[(V_b-V_B)^(-1)](b-B)
= 9.65
Prob>chi2 = 0.0858
(V_b-V_B is not positive definite)
p值为0.0858,虽然在5%的显著性水平上无法拒绝原假设“$H_0:u_i$与解释变量不相关”,但是在10%的显著性水平上可以拒绝,认为应该使用固定效应而非随机效应模型。
(7):稳健的豪斯曼检验
qui xtreg lny lnk1 lnk2 lnlabor unemp, r
xtoverid
结果:
Test of overidentifying restrictions: fixed vs random effects
Cross-section time-series model: xtreg re robust cluster(state)
Sargan-Hansen statistic 19.333 Chi-sq(4) P-value = 0.0007
检验的结果是强烈拒绝随机效应的原假设。
(8):组内估计 + 时间趋势
. xtreg lny lnk1 lnk2 lnlabor unemp year, fe r
Fixed-effects (within) regression Number of obs = 816
Group variable: state Number of groups = 48
R-sq: Obs per group:
within = 0.9475 min = 17
between = 0.9883 avg = 17.0
overall = 0.9864 max = 17
F(5,47) = 383.39
corr(u_i, Xb) = 0.8393 Prob > F = 0.0000
(Std. Err. adjusted for 48 clusters in state)
------------------------------------------------------------------------------
| Robust
lny | Coef. Std. Err. t P>|t| [95% Conf. Interval]
-------------+----------------------------------------------------------------
lnk1 | -.0283785 .0610049 -0.47 0.644 -.1511046 .0943477
lnk2 | .1434502 .0826932 1.73 0.089 -.0229069 .3098074
lnlabor | .725201 .0840044 8.63 0.000 .5562061 .894196
unemp | -.0076736 .0023959 -3.20 0.002 -.0124935 -.0028537
year | .0070499 .0014881 4.74 0.000 .0040561 .0100437
_cons | -9.686101 2.439071 -3.97 0.000 -14.59288 -4.779322
-------------+----------------------------------------------------------------
sigma_u | .21134823
sigma_e | .03608959
rho | .97166754 (fraction of variance due to u_i)
------------------------------------------------------------------------------
时间趋势项是显著的。
(9):组内估计 + 时间虚拟变量
. tab year, gen(year)
. xtreg lny lnk1 lnk2 lnlabor unemp year2-year17, fe r
Fixed-effects (within) regression Number of obs = 816
Group variable: state Number of groups = 48
R-sq: Obs per group:
within = 0.9536 min = 17
between = 0.9890 avg = 17.0
overall = 0.9879 max = 17
F(20,47) = 364.45
corr(u_i, Xb) = 0.7201 Prob > F = 0.0000
(Std. Err. adjusted for 48 clusters in state)
------------------------------------------------------------------------------
| Robust
lny | Coef. Std. Err. t P>|t| [95% Conf. Interval]
-------------+----------------------------------------------------------------
lnk1 | -.0301757 .0582405 -0.52 0.607 -.1473404 .0869891
lnk2 | .1688277 .0856799 1.97 0.055 -.0035381 .3411934
lnlabor | .7693063 .0850678 9.04 0.000 .5981719 .9404406
unemp | -.0042211 .0031954 -1.32 0.193 -.0106494 .0022072
year2 | .015136 .0033617 4.50 0.000 .008373 .0218989
year3 | .029522 .0045477 6.49 0.000 .0203732 .0386708
year4 | .0425394 .0076907 5.53 0.000 .0270677 .058011
year5 | .0152535 .0103313 1.48 0.146 -.0055304 .0360374
year6 | .0158935 .0137346 1.16 0.253 -.0117369 .0435239
year7 | .0231792 .0138496 1.67 0.101 -.0046827 .051041
year8 | .0312112 .014556 2.14 0.037 .0019283 .0604941
year9 | .0387562 .0164337 2.36 0.023 .0056959 .0718165
year10 | .0360904 .0188087 1.92 0.061 -.0017478 .0739287
year11 | .0274387 .0223685 1.23 0.226 -.017561 .0724384
year12 | .0442891 .0233254 1.90 0.064 -.0026355 .0912136
year13 | .0419059 .0258024 1.62 0.111 -.0100018 .0938136
year14 | .0588273 .0258947 2.27 0.028 .0067339 .1109206
year15 | .0784954 .0249182 3.15 0.003 .0283665 .1286243
year16 | .0873012 .0263323 3.32 0.002 .0343275 .1402749
year17 | .0979994 .02765 3.54 0.001 .0423749 .153624
_cons | 3.637237 .679395 5.35 0.000 2.270471 5.004004
-------------+----------------------------------------------------------------
sigma_u | .15633758
sigma_e | .0342888
rho | .95410413 (fraction of variance due to u_i)
------------------------------------------------------------------------------
. local cmd = ""
. forval i = 2/17{
2. local cmd "`cmd' year`i'"
3. }
. di "`cmd'"
year2 year3 year4 year5 year6 year7 year8 year9 year10 year11 year12 year13 year14
> year15 year16 year17
. test `cmd'
( 1) year2 = 0
( 2) year3 = 0
( 3) year4 = 0
( 4) year5 = 0
( 5) year6 = 0
( 6) year7 = 0
( 7) year8 = 0
( 8) year9 = 0
( 9) year10 = 0
(10) year11 = 0
(11) year12 = 0
(12) year13 = 0
(13) year14 = 0
(14) year15 = 0
(15) year16 = 0
(16) year17 = 0
F( 16, 47) = 28.90
Prob > F = 0.0000
时间效应显著。
(10):FD
* net install st0039.pkg, from("http://www.stata-journal.com/software/sj3-2/")
xtserial lny lnk1 lnk2 lnlabor unemp year2-year17, output
结果:
. xtserial lny lnk1 lnk2 lnlabor unemp year2-year17, output
Linear regression Number of obs = 768
F(20, 47) = 363.63
Prob > F = 0.0000
R-squared = 0.8539
Root MSE = .01845
(Std. Err. adjusted for 48 clusters in state)
------------------------------------------------------------------------------
| Robust
D.lny | Coef. Std. Err. t P>|t| [95% Conf. Interval]
-------------+----------------------------------------------------------------
lnk1 |
D1. | -.0416268 .0440097 -0.95 0.349 -.130163 .0469093
|
lnk2 |
D1. | .0062043 .0257296 0.24 0.810 -.0455569 .0579656
|
lnlabor |
D1. | .9050566 .0362855 24.94 0.000 .8320596 .9780535
|
unemp |
D1. | -.002949 .0009908 -2.98 0.005 -.0049422 -.0009558
|
year2 |
D1. | .0193292 .003322 5.82 0.000 .0126461 .0260123
|
year3 |
D1. | .0333364 .0052652 6.33 0.000 .0227441 .0439287
|
year4 |
D1. | .0465709 .0087431 5.33 0.000 .028982 .0641598
|
year5 |
D1. | .0229254 .0092568 2.48 0.017 .0043031 .0415476
|
year6 |
D1. | .028394 .0106514 2.67 0.010 .0069662 .0498217
|
year7 |
D1. | .0380152 .012365 3.07 0.004 .0131401 .0628903
|
year8 |
D1. | .0441399 .0141835 3.11 0.003 .0156065 .0726734
|
year9 |
D1. | .0502516 .0155829 3.22 0.002 .0189028 .0816003
|
year10 |
D1. | .0491132 .0165744 2.96 0.005 .0157699 .0824565
|
year11 |
D1. | .045003 .0167655 2.68 0.010 .0112752 .0787307
|
year12 |
D1. | .0643423 .0177688 3.62 0.001 .0285962 .1000885
|
year13 |
D1. | .0668306 .0172853 3.87 0.000 .032057 .1016041
|
year14 |
D1. | .0852646 .0177724 4.80 0.000 .0495112 .1210181
|
year15 |
D1. | .1034262 .0190686 5.42 0.000 .065065 .1417874
|
year16 |
D1. | .1135096 .020332 5.58 0.000 .0726068 .1544123
|
year17 |
D1. | .1269322 .0217636 5.83 0.000 .0831494 .170715
------------------------------------------------------------------------------
Wooldridge test for autocorrelation in panel data
H0: no first-order autocorrelation
F( 1, 47) = 121.713
Prob > F = 0.0000
$lnk_1$系数为负,不显著。
(11):组间估计量
. xtreg lny lnk1 lnk2 lnlabor unemp, be
Between regression (regression on group means) Number of obs = 816
Group variable: state Number of groups = 48
R-sq: Obs per group:
within = 0.9330 min = 17
between = 0.9939 avg = 17.0
overall = 0.9925 max = 17
F(4,43) = 1754.11
sd(u_i + avg(e_i.))= .0832062 Prob > F = 0.0000
------------------------------------------------------------------------------
lny | Coef. Std. Err. t P>|t| [95% Conf. Interval]
-------------+----------------------------------------------------------------
lnk1 | .1793651 .0719719 2.49 0.017 .0342199 .3245104
lnk2 | .3019542 .0418215 7.22 0.000 .2176132 .3862953
lnlabor | .5761274 .0563746 10.22 0.000 .4624372 .6898176
unemp | -.0038903 .0099084 -0.39 0.697 -.0238724 .0160918
_cons | 1.589444 .2329796 6.82 0.000 1.119596 2.059292
------------------------------------------------------------------------------
由于豪斯曼检验选择了固定效应,而组间估计量只在随机效应成立的情况下才是一致的,所以其结果不可信。